Free AI, powered by the crowd
Chat with open models for free — served by GPUs worldwide. Contribute compute, earn credits. No signup.
Prompts are processed by distributed GPU nodes. Don't share passwords or API keys.
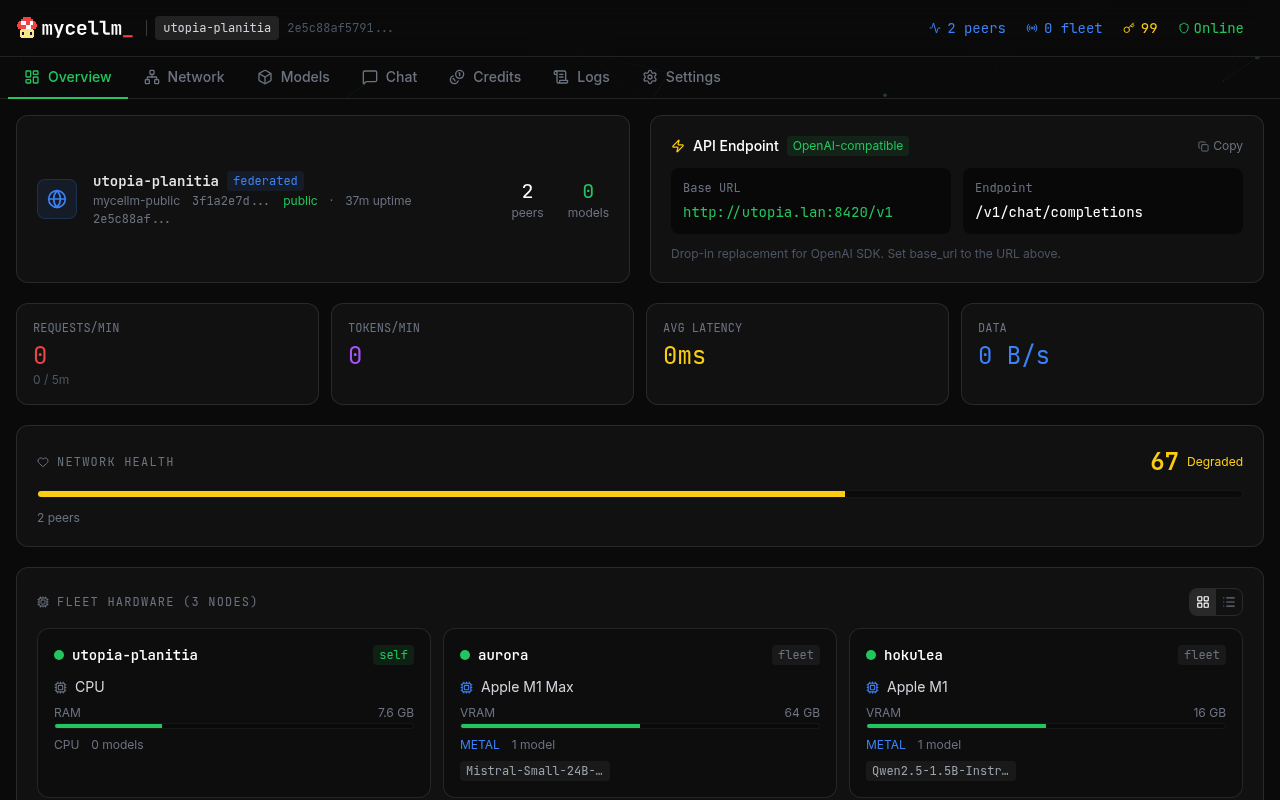
Why distributed inference?
Models run across multiple peers. If one goes down, requests automatically route to another — no downtime.
Contribute idle compute and earn credits. Spend them to run larger models across the network. A fair exchange.
Drop-in OpenAI-compatible API. Switch from any provider with one env var. Your tools, your choice.
Run your own swarm or federate with trusted peers. Control membership, models, and data with cross-network routing.
Apache 2.0 licensed. Audit the code, fork it, extend it. Every layer is transparent — no black boxes, no hidden costs.
Every new seeder makes the network faster and more capable. More contributors means more models and lower latency.
Drop-in OpenAI replacement
Change one env var. Everything else stays the same.
Sensitive Data Guard
Outgoing prompts are scanned on-device for API keys, passwords, and PII. High-severity matches automatically route to your local model — sensitive data never leaves your device.
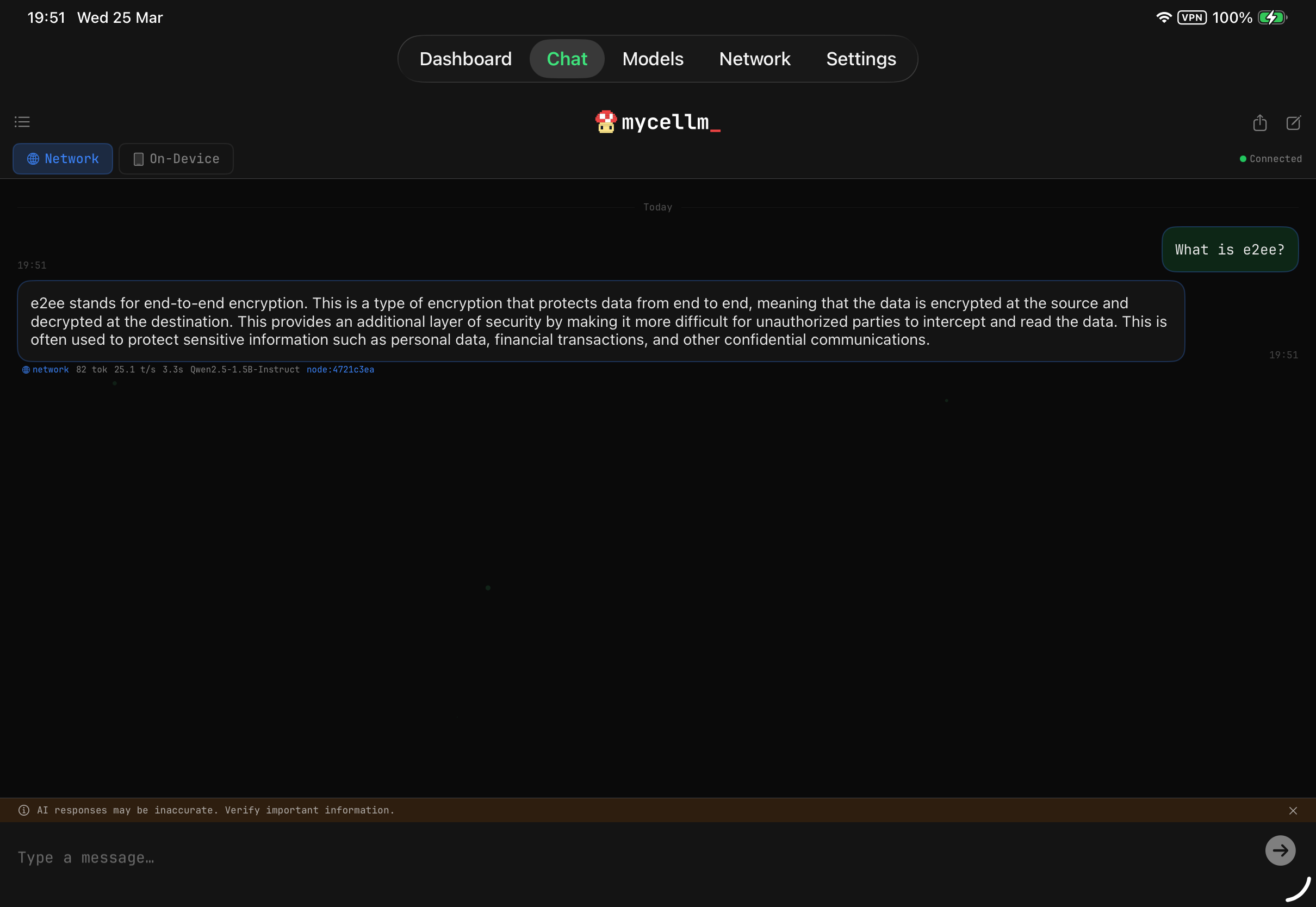
Your iPad is a full peer on the network — serve inference at 30+ tokens/sec on Metal, earn credits, and chat with persistent threads and privacy protection.
Also works on iPhone.